Comprobar si dos archivos son idénticos es una tarea trivial ya que es posible compararlos byte a byte o bien, calcular un hash de cada archivo y comparar dichos valores. Pero intentar comparar la similitud del contenido de dos archivos es algo menos trivial.
Este curso fue impartido internamente para el equipo técnico de Freepik en 2021 a modo de charla técnica y, posteriormente, publicada en el blog de ApiumHub en 2022 tras mi paso como empleado en ambas compañías.
Esta charla se ha diseñado como una guía práctica de introducción a los perceptual hashes donde se podrá...
- Comprender los diferentes tipos de hashes.
- Entender cómo funcionan los perceptual hashes.
- Implementar perceptual hashes con PHP.
- Aplicar los pHashes a un caso de uso práctico.
Esta formación está orientada principalmente a desarrolladores/as de software que tengan especial interés en entender cómo aplicar conceptos avanzados de tratamiento de imágen por ordenador en sus proyectos.
La metodología de esta guía se basa en:
- Teoría y conceptos, con explicaciones claras y concisas de los puntos clave.
- Demostraciones, con ejemplos reales y cotidianos.
Para aprovechar al máximo este recurso se necesita:
- Un equipo con acceso a Internet.
- Privilegios de administrador para instalar software.
- Conocimientos básicos de desarrollo web.
En términos generales para comparar dos archivos basta con analizar byte a byte sus contenidos o bien, usando un hash sobre sus contenidos y comparar dichos valores. Pero cuando se trata de imágenes la problemática se complica ligeramente.
Comparar los metadatos (datos EXIF, fecha y hora de creación, tamaño de la imágen...) no garantiza que ambos archivos contengan el mismo contenido y, además, los algoritmos de compresión de imágenes impiden comparar byte a byte el contenido de dos imágenes debido a la propia naturaleza con pérdidas de los algoritmos de compresión.
Existen formatos de imágenes que garantizan una compresión sin pérdidas como PNG. Este formato genera un archivo de mayor tamaño en comparación con otros formatos de compresión pero garantiza que no hayan pérdidas en el proceso.
Por el contrario, cuando se codifica y descodifica una imagen JPEG se obtienen ficheros de menor tamaño a costa de cambian o perder algunos datos "visualmente irrelevantes".
LLegados a este punto, si no podemos/debemos usar los metadatos... ¿cómo podemos determinar si dos archivos de imágen tienen el mismo contenido?
Como respuesta corta: no podemos.
Lo que sí podemos es determinar un vector de similitud, es decir, cuantificar cómo de similiares son dos archivos de imágen entre sí.
Existe una gran diversidad de hashes o de algoritmos que generan "huellas digitales" únicas de longitud fija para diferentes tipos de datos, lo que permite que sean utilizados en tareas de verificación de integridad durante la transferencia de archivos, la seguridad de contraseñas, etc.
Los algoritmos más frecuentes son MD5, SHA-1, SHA-2 (con variantes como SHA-256 y SHA-512) y SHA-3.
Grosso modo estos algoritmos criptográficos de hashing están diseñados para generar un resultado impredecible ya que están creados para ser unidireccionales y generar huellas digitales únicas, difíciles de invertir o manipular. Son sensibles a pequeñas variaciones en los datos de entrada..
En cambio, existen los llamados hashes perceptivos que actúan completamente en el sentido opuesto: están diseñados para ser tolerantes a pequeñas variaciones, buscando capturar la esencia o "percepción" del contenido. Son más útiles para comparar similitudes que para la seguridad.
Hashes perceptivos más frecuentes:
- Average Hashing (aHash)
- Median Hashing (mHash)
- Perceptual Hashing (pHash)
- Difference Hashing (dHash)
- Block Hashing (bHash)
- Wavelet Hashing (wHash)
- ColorMoment Hashing
En esta formación me centraré en el algoritmo de Perceptual Hashing (pHash) que calcula el hashing sobre la Transformada Discreta de Coseno (DCT) que convierte los datos del dominio espacial al dominio de la frecuencia.
Tal y como se ha comentado anteriormente, esta familia de algoritmos está diseñada para tolerar cuando una imagen sufre pequeñas modificaciones como la compresión, la corrección del color y el brillo.
Los pHashes permiten comparar dos archivos teniendo en cuenta el número de bits representativos diferentes. Esta diferencia se conoce como distancia de Hamming.
Veamos cómo funciona el perceptual hash con una imágen de ejemplo:
Escogemos una imágen de ejemplo:

Convertimos la imágen a escala de grises:

Generamos una imagen de 32x32 con un factor de 4:

A esta imagen se le aplica una transformada de coseno discreto, primero por fila...
... y luego por columna.
Los píxeles con frecuencias altas se encuentran ahora en la esquina superior izquierda, por lo que la imagen se recorta en los 8x8 píxeles superiores izquierdos.
A continuación, calcula la mediana de los valores de gris de esta imagen:
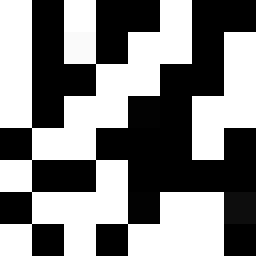
Y por último, convertimos esa imagen en un hash donde cada pixel blanco es un 1 y cada pixel negro es un 0:
1010010010101101100110011011001101100010100100000111011010101110
Ahora que sabemos cómo calcular el pHash, veamos cómo podemos aplicarlo:
$phash1 = '0011110000111110000011100001101000111010000111100001111000011110';
$phash2 = '0011110000111110000011100001101000111010000111100001111000011110';
echo levenshtein($phash1, $phash2); // Result: 0
$phash1 = '0011110000111110000011100001101000111010000111100001111000011110';
$phash2 = '0011110000111110000011100011111000111110000111100001111000011110';
echo levenshtein($phash1, $phash2); // Result: 3
$phash1 = '0010100010101000101010001010100010101011001010110101011100110111';
$phash2 = '0111000011110000111100101101001101011011011101010011010101001111';
echo levenshtein($phash1, $phash2); // Result: 32
Estos son algunos de los casos de uso frecuentes para los perceptual hashes:
- Detección de contenido duplicado
- Permite identificar imágenes idénticas o muy similares que se encuentran en diferentes ubicaciones o bases de datos. Esto es útil para la gestión de contenido multimedia, evitando la duplicación de archivos y reduciendo el espacio de almacenamiento.
- Búsqueda visual
- Los hashes perceptuales facilitan la búsqueda de imágenes similares a una imagen dada. Al comparar los hashes perceptuales de diferentes imágenes, se pueden encontrar resultados relevantes incluso si las imágenes no tienen las mismas etiquetas o descripciones.
- Moderación de contenido en redes sociales
- Ayudan a identificar y eliminar contenido que viola las políticas de las plataformas, como imágenes que promueven el odio, la violencia o el material sexual. Al comparar el hash de una imagen con una base de datos de imágenes prohibidas, se puede automatizar el proceso de detección y eliminación.
- Gestión de derechos digitales (DRM)
- Se pueden utilizar para proteger los derechos de autor de las imágenes. Al generar un hash perceptual de una imagen y compararlo con hashes de otras copias, se puede identificar si la imagen está siendo utilizada sin permiso.
- Creación de bases de datos de imágenes
- Permiten crear bases de datos eficientes de imágenes similares, lo que facilita la búsqueda y organización de grandes conjuntos de datos visuales.
- Análisis forense digital
- Pueden ser utilizados para identificar imágenes manipuladas o alteradas, así como para rastrear el origen de imágenes específicas.
- Reconocimiento de objetos
- Aunque no es su función principal, los hashes perceptuales pueden ser utilizados en sistemas de reconocimiento de objetos, especialmente cuando se trata de identificar objetos en diferentes condiciones de iluminación o desde diferentes ángulos.
Para complementar esta formación se aporta una implementación de buscador por imágen (reverse image search engine) en PHP.
Este caso de uso está basado en Nike.es, la conocida web de marca deportiva.
Si comparamos la aplicación nativa con su website podemos ver que hay diferencias cuando realizamos una búsqueda de zapatillas:
- Aplicación nativa
-
Al usar la aplicación nativa se puede encontrar zapatillas navegando por su catálogo, introduciendo el nombre del modelo en el buscador o tomando una foto de la zapatilla deseada.
Si hay una coincidencia, la aplicación redirige al usuario a la vista de detalles del producto correspondiente; en caso contrario, el catálogo se reordena para mostrar las zapatillas ordenadas por similitud con la deseada.
- Website
- Al usar la aplicación web esta funcionalidad no existe. Es decir, no hay ninguna manera de filtrar zapatillas por similitud.
La funcionalidad de búsqueda de zapatillas mediante foto dejó de estar incluída en la aplicación nativa de Nike desde hace unos años.
Curiosamente Adidas si que incorpora dicha funcionalidad en su aplicación nativa.
El repositorio de ejemplo no es un clon completo ni una versión funcional de todo el sitio web de Nike.es.
Es una prueba de concepto basada en un componente reactivo de VueJS que hace uso de una pseudo API en PHP que integra la lógica de búsqueda por similitud.
Puedes ver el código fuente en el siguiente repositorio https://github.com/AlcidesRC/cv-searching-similar-images